Part-4 : What is Data Science
I hope you have went through the last chapters otherwise I will strongly recommend you go through them at least once.
In last chapters we have developed some familiarity with the terms like machine learning, statistics and their roots.
In this chapter we will focusing on how these terms fits together.
This will provide better understanding and prevent you from getting confused with terms like AI , Data Science and all .
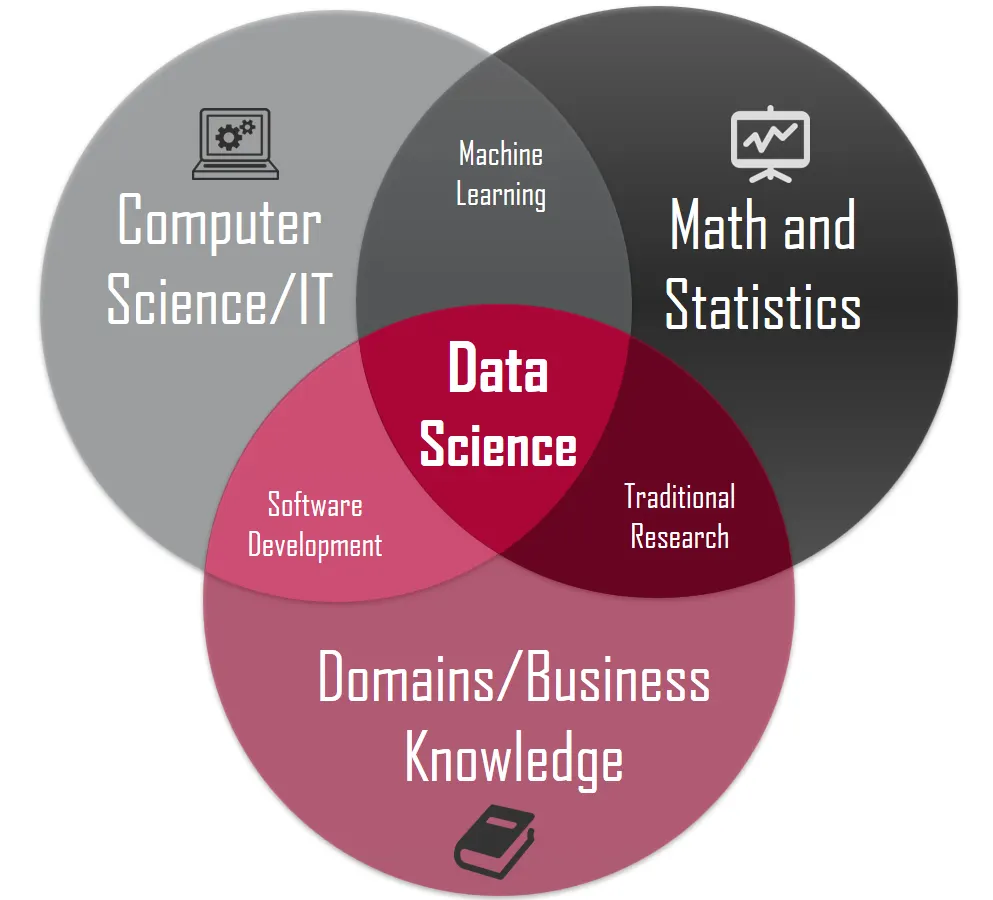
We can see here there are three major roots — CSE, MATH, DOMAIN/BUSINESS
The machine learning algorithms (or what we generally say machine learning) is intersection of MATH(specifically statistics and probablility) and CS/IT .
Traditional research comprises of ongoing research and development on methods it could be addition or update .
DOMAIN/BUSINESS — implies in whatever specific field like — neuroscience, games, where we want to apply Data Science. Here is the reason for specially pointing out “business” — most of the initial and even current motivation for interest in Data science is due to the demand of its application in this sector.
what is the difference between machine learning, data science, statistics, probability ?
Statistics
- branch of applied mathematics
- deals with data collection, organization, analysis, interpretation and presentation(source) (there isn’t any thing like prediction)
Probability Theory
- branch of theoretical mathematics
- deals with probabilities, likelihood
One thing is clear from above definitions that they both are different thing.
Lets take an example -
domain of f is { PRESS } , output of f in continuous fashion at each press is {2,4,6,8,10,12,……..} and
Input( PRESS )→[ system or f()] → Output
Now, we will watch this whole output generation process from some distance and see how things will approach this system & play role in it .
Probability theory will see this as a system which is generating some numbers. Now It will say ok, I can do one thing for you when you will be going to press the button I can tell “what is the probability of your expected output” . It will also ask if you know something extra about this system (anything you know extra about such system is called bias) and wants to use it . You might will say yes- I have seen last output was 2 and use it. So it also consider it as now it will calculate probability or possibility or likelihood of coming any output provided 2 has already came.
In this case by considering some facts like if system is biased, possible inputs to the system, possible outputs of the system , we build an idea that what is the possibility or likelihood that the system will generate this output. We didn’t even bothered to look if the generated numbers are in A.P. so next number will be this.
Statistics will observe the system for suppose 6 rounds({2,4,6,8}) and prepares a table of outputs in consecutive turns and try to figure out what underlying process(f()) would explain those observations. What is the average value of outcomes, whats the frequency of outcomes etc (analysis), we could use this analysis to say things like mean is 5 so next output should be mostly around this so I will bet on 4 or 6 for the next round also. what could be the next number based on plotted graph if we see line in plotted graph(presentation) , It will say ok- there is linear dependency between them and then using simple equation of line we might be able to find out exact f(), and hence the exact future outputs.
To know more about how they differ check this out.
In probability , probability itself has answered something about next upcoming output-likelihood(It didn’t predicted anything for you, instead it added a number representing what is the probability of your prediction) .
In statistics after we got the analysis and presentation, we worked with analysis and presentation(plot) and our complex brain has found plot is straight line. So next we planned to find out f(), and use it accordingly to predict exactly the next output.(we are doing these works)
Again as we have seen that as the computation load increases, we tend to find a solution. Here the load was to recognizing the pattern its AP, its straight line .
Machine learning will say “ok,humans I have got your back” . You can program your computer using my algorithm , which will make your system to learn and then machine will be doing this pattern finding for you.
I guess you have the clear idea of how they differ .
Conclusion is Probability does not mind at all about the system, its your choice tell her whatever you want as input, and then it will tell you about the probability of next output. Statistics will see and wait of certain moves to collect data and with the already defined functions like mean, mode , frequency, deviation, variance it will generate a report , it will also plot these data for you And say here take this analysis report and plot and using your brain do whatever you want to do. Machine learning will see the situation and will ask you do one thing just program my algorithm in your system and give me the experience(data) and then you don’t have worry any more for predicting the next output, I will do it for you.
Coming onto Data Science -
Let’s start this definition starting from here -
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured.
So, it intersects with other fields(multi-disciplinary) as it can be seen in above picture.
Difference between Data Science , Data mining and KDD
Here, We should make one thing clear that Data mining is just a step of KDD process. Now, our point of discussion will be Data Science and KDD.
The difference lies in there origins.
Everything starts from a need and then questions lead the path for its fulfillment.
In 80’s when database system was evolving,We felt need of system which will be able to fulfill our other need to answer queries like -
select * students where student.course == CSE
We came to Advance Database Systems to fulfill this need of these smart queries .
Now, who has these databases, generally enterprises. So, a day came when enterprise’s database become bigger, they felt we could do better, we could extract more information from these databases.And these extra information is nothing else then “pattern”. We started to think to bring a new method which will discover patterns and information/knowledge from the datasets/databases for us.
There to fulfill this need of more information extraction or patterns we started Knowledge Discovery in Databases. Although if we see the timeline, we will find that the term data mining came before KDD but as it started growing people involved with it felt that we need to see this term as more academic POV for better results and there they started KDD which was not only focused on Data mining instead it also covers data processing and presentation steps also.
The term data science is given to the fulfillment of the need — To study, understand and apply the scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured.
The need of data science is “data-centric”, — Yes, I have data, what can I do with it , how to do it, what I have to do with it before doing what I can to do with it ?
While the need of KDD is “database-centric”- Yes, I have this database, how can I perform better queries, how to do that, what I have to do with it before doing what I can to do with it ?
The time when KDD is established, there was only business needs. But as the time progressed , now we have needs in other domains also.
Although, KDD was started as independent branch but now we can see it as special case of Data Science where the domain==business.
I hope the definitions , similarities and dissimilarities are clear.
Coming back to our last point of interest which is AI
Remember when we started this series we discussed a scenario where we assigned our job to other human and in return that human required salary from ous . So, We came to understand that although we humans are capable of doing great things but there is some limit and restrictions we can not do certain tasks or maybe we do not want to(mostly). So, instead to fulfill the need of human to complete our certain tasks leads to development of another need — a artificial human or say artificial intelligence. The goal of this AI is to perform tasks at which we humans are very good at it and in addition it should do more than us.
Wow, I guess we are done here. I sincerely hope this trip has been amazing, same as it was amazing for me.
Any feedback,suggestion and correction is welcomed. Contact me.
- Part 0 :Where it all starts — Is Data Science different from Statistics
- Part 1 : Don’t lose the basics — What is Statistics ?
- Part 2 : Bonus Knowledge — Theory vs Hypothesis vs Predictions
- Part 3 : Strengthen your basics — Machine Learning vs Statistics ?
- Part 4: Where it all ends — What is Data Science & the complete picture ?
